
Powering Discoveries
Accelerating Deep Learning
Solving science and engineering problems with supercomputers and AI
Scientific computing applications traditionally start from "first principles," mathematical formulas representing the physics of a system. They then transform those formulas into forms that can be solved by distributing the calculations to many processors.
By contrast, machine and deep learning rapidly scan very large datasets to find subtle connections in information. From those connections, they can rapidly generate, test, and optimize solutions. These capabilities let scientists derive the governing models (or workable analogs) for complex systems that cannot be modeled from first principles.
Machine learning uses algorithms that "learn" from data and improve performance based on real-world experience. Deep learning, a branch of machine learning, relies on large data sets to iteratively "train" many-layered neural networks inspired by the human brain. These trained neural networks then use a process known as inference to apply what was learned to new data.
Training can be a complex and time-consuming activity. But once a model has been trained, it is fast and easy to interpret each new piece of data to recognize, for example, cancerous versus healthy brain tissue, or enable a self-driving vehicle to identify a pedestrian crossing a street.
In Search of Deep Learning Trainers: Heavy Computation Required
Just like traditional HPC, training a neural network or running a machine learning algorithm requires extremely large numbers of computations — quintillions! — making them a good fit for supercomputers and their tens of thousands of parallel processors.
In 2018, researchers from TACC, the University of California, Berkeley and the University of California, Davis, set a record for the fastest training of a neural network to classify images. The team used large batch sizes — essentially big chunks of a dataset — and the newly developed Layer-wise Adaptive Rate Scaling (LARS) algorithm, to speed up deep neural networks training on Stampede2.
They tested the effectiveness of the method on two neural networks, AlexNet and ResNet-50, trained with the ImageNet-1k dataset — a common benchmark for deep neural network training. Using 2,048 Intel Xeon processors, they reduced the 100-epoch AlexNet training time from hours to 11 minutes. They also reduced the 90-epoch ResNet-50 training time from an hour to 20 minutes. (An epoch refers to one full pass through the entire training dataset.) Their approach showed higher test accuracy than previous efforts by Facebook researchers on batch sizes larger than 16,000.
The research won the Best Paper award at the 2018 International Conference on Parallel Processing.
High-speed, high-accuracy image classification can be used to characterize satellite imagery for environmental monitoring or to label nanoscience images obtained by scanning electron microscopes.
"These results show the potential of using advanced computing resources, like those at TACC, along with large mini-batch enabling algorithms, to train deep neural networks interactively and in a distributed way," said Zhao Zhang, a research associate at TACC. "Given our large user base and huge capacity, this will have a major impact on science."
TACC has, in recent years, created a complete ecosystem for machine learning and deep learning-based research. This includes systems like Maverick2 that are tailor-made for training deep neural networks, and support for a number of popular deep learning frameworks, including Caffe, MXNet, and TensorFlow.
These investments will impact the speed of science, as well as the kinds of projects that researchers can explore with these new methods.
Successes in Critical Applications
To date, researchers have used TACC to apply machine and deep learning to a range of important science and engineering problems.
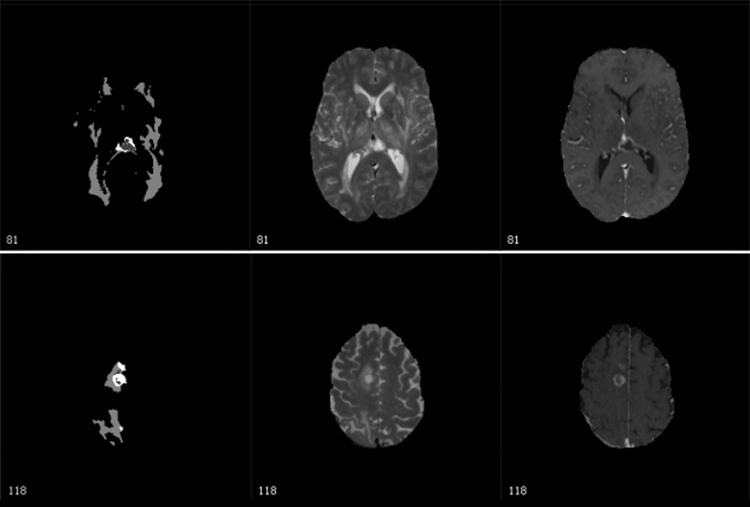
Engineers from UT Austin and the University of Pennsylvania used Stampede2 to train a brain tumor identification and classification system that can recognize tumors with greater than 90 percent accuracy, roughly equivalent to an experienced radiologist. The team will soon begin using the system for clinical studies of brain tumors.
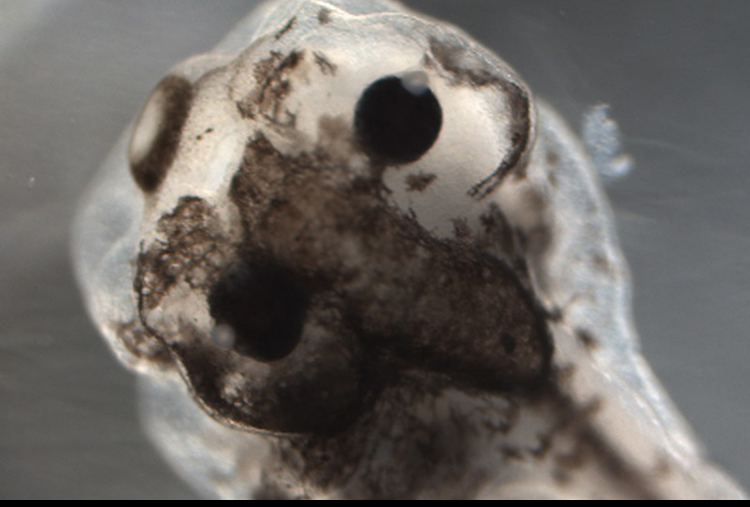
Researchers from Tufts University and the University of Maryland, Baltimore County, used machine learning on Stampede1 to model the cellular control network that determines how tadpole pigmentation develops and to reverse-engineer tadpoles with a form of mixed pigmentation never before seen in nature.
Atmospheric scientists from the University of Oklahoma used Stampede2 to develop machine learning-derived hail forecast algorithms for severe weather forecasting that will one day be able to warn the public about hailstorms hours in advance.