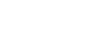

Powering Discoveries
Aaron Dubrow
Related Links
High Performance AI
Transforming science with deep learning and HPC
Machine learning and deep learning have taken science and society by storm, offering new ways to make discoveries, predict behavior, and guide decision-making.
Just like traditional high performance computing, training a deep neural network or developing a machine learning algorithm requires extremely large numbers of floating point operations (quintillions!) — making them a good fit for supercomputers and their thousands of parallel processors.
To help situate you in the fast-evolving world of AI, we’ve created a primer of terms, tools, and technologies that TACC is applying to help researchers use machine and deep learning effectively.
Deep Learning
Challenges
Data Overload:
Training a neural network can require a system to read data up to 180 million times and perform 2,000 input/output (I/O) operations per second. These demands can cause a shared parallel file system to shut down or become unresponsive.
TACC
Solutions
FanStore:
A system developed at TACC intercepts I/O traffic and processes it on the compute node to reduce the data workload on the shared file system, achieving 71-99% of the performance of a solid state storage device.
Software Management:
Deep learning frameworks change frequently and rely on multiple dependencies from the operating system to the interface.
Divide and conquer:
TACC manages low-level systems and libraries; users manage instances of their preferred frameworks.
Scaling Code:
Using multiple GPUs or CPUs can speed up training and allow researchers to tackle bigger problems, but few know how to do so.
Training
Create guidelines and training to help researchers scale their deep learning problems to many processors.
Human Interpretability:
Science demands that a solution be explainable, but neural networks are frequently black boxes.
AI Forensics:
Support interpretable deep learning that can demonstrate that a model is capturing the correct information and show how the neural network came to its conclusion.
Data-Poor Problems:
Not all science problems have the massive amounts of data needed for traditional training.
Exploit Sparsity:
Employ refinement approaches like interpolation and cost function mitigation to overcome this data deficiency.
Implausible Results:
Neural networks that don't incorporate known physics or features of a physical system have the potential to produce implausible solutions.
Integrate Scientific Knowledge into Deep Learning
Develop methods that blend deep learning with physics-based constraints to advance domain science.
How does Deep Learning Work?
Deep learning uses neural networks to make decisions. Data is supplied to the network and “hidden layers” of “neurons” recognize characteristics of the data. A simple example might be a color-based network with “is white” and “is blue” as outputs. By itself, the network does nothing, but given a large set of data, and examples of images that are labeled as “white” or “blue”, the network can “learn.”
This process of deep learning uses an iterative, two-step procedure that includes a forward step and a backward step. The forward step applies defined transformations in each unit along the neural network to sampled training data and computes a loss function. This loss (also referred to as training loss) is a statistical measure of the likelihood that the prediction is accurate. The backward step then calculates the gradient (steepness) of the loss function with regard to weights, and passes these gradients backward through the same network. The neurons can then be refined so their weights are updated to better infer ground truth from inputs. This process is repeated until a satisfactory solution is reached. In the simplistic case, the neural network would learn that clouds are white and the sky is blue (and would ignore data that are red).
There are many different characteristics that a network can learn. These networks can have many different neurons in a layer and multiple layers to enable better inference from input data, much the way our own brain recognizes the world around us.
Classes of Deep Learning
RNN: Recurrent Neural Networks
Deep neural network with neurons forming a one-way, non-repeating graph along a temporal sequence.

Predicting fusion reactor disruptions using status update data in a time series.
CNN: Convolutional Neural Networks
Deep neural networks centered around convolution: a mathematical operation on two functions to produce a third function that expresses how the shape of one is modified by the other.
Treatment progress monitoring using magnetic resonance imaging (MRI) analysis.
RL: Reinforcement Learning
An area of machine learning that trains an agent to interact with some environment with the goal of maximizing a reward.

Energy control on Mars rover.
GAN: Generative Adversarial Networks
Deep learning algorithms with two neural networks acting as a generator and a discriminator, respectively. The generator produces synthetic data and the discriminator tries to differentiate the synthetic data from the true data.
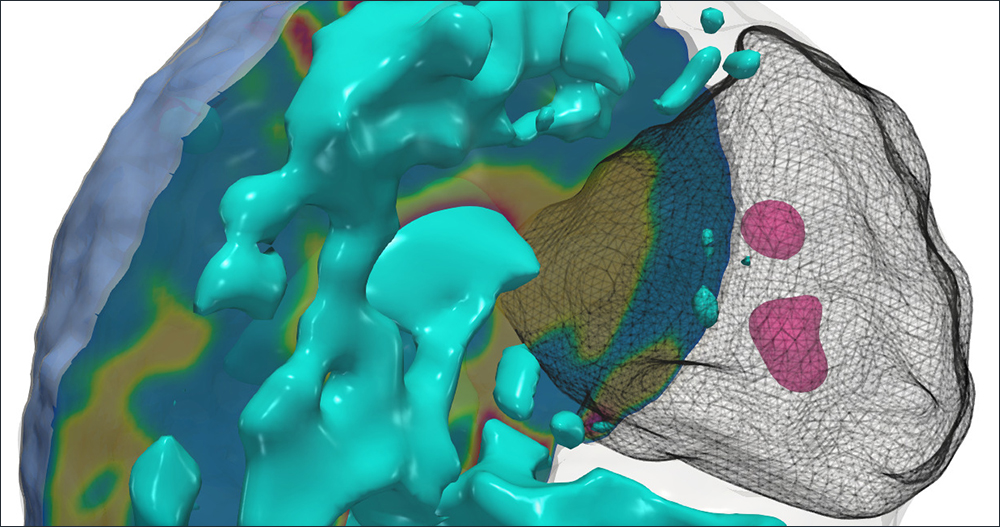
Enhancing resolution of electron microscope images.