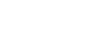

Feature Stories
Aaron Dubrow
Related Articles
AI Engineers the World
Researchers use TACC supercomputers to train AI for civil engineering, manufacturing, and biomedical modeling

Over the past half century, computers have become essential to engineering, helping design faster and safer airplanes, longer-lasting heart valves, and the nanoscale circuits that power our digital world.
In the last decade, engineers have begun applying artificial intelligence, in the form of machine and deep learning, to aid in the design process. This approach is useful when the underlying physics of the problem is difficult to model, or when no model exists to predict a system’s behavior.
It’s also helpful when you need a model that can make informed predictions rapidly. When a hurricane is approaching, for example, the application of deep learning capabilities to a new scenario can make all the difference in how timely the emergency response can be.
However, training an AI model is no simple matter. Large-scale computing horsepower is needed to identify a predictive and efficient artificial neural network.
While Amazon and Google have the capacity to train a large neural network in-house, few universities in the world have these capabilities. TACC, however, does. This has made the center an active hub for AI research — and an example of how federally-funded supercomputers are supercharging engineering and allowing hundreds of academic researchers to rapidly train and test AI models.
“The combination of AI, traditional computational modeling, and supercomputers is enabling new ways to engineer systems and new pathways to discovery,” said TACC Executive Director Dan Stanzione. “This approach will help build a more resilient, sustainable world.”
AI and the Engineered Environment
In terms of large-scale engineering challenges, city planning and structural engineering are two that impact us all. Our cities, neighborhoods, and homes are all engineered environments, and the quality of that engineering matters, especially in areas where natural disasters occur.
Understanding the amount of damage a community may face in the future helps engineer more resilient communities. “That understanding is what simulation and modeling can provide,” said Charles Wang, assistant professor in the College of Design, Construction and Planning at the University of Florida.
As a member of the NHERI SimCenter, headquartered at UC Berkeley, Wang co-developed a suite of AI-based engineering tools called BRAILS — Building Recognition using AI at Large-Scale. BRAILS applies deep learning — multiple layers of algorithms that progressively extract higher-level features from the raw input — to automatically classify features in millions of structures in a city. Architects, engineers, and planning professionals can use these classifications to assess risks to buildings and infrastructure, and they can even simulate the consequences of natural hazards.
BRAILS’s objectives are two-fold. “First, to mitigate future damage by improving simulation inputs to inform key stakeholders. And second, to generate data ahead of time to quickly simulate a real scenario as it approaches or immediately following an event, and before a reconnaissance team is deployed, to guide emergency response with greater accuracy,” Wang explained.
To train BRAILS and run city-wide natural hazard simulations in their Regional Resilience Determination (R2D) Tool, SimCenter researchers employed Frontera and Maverick2, a system designed for deep learning.
For this type of problem, “machine learning is really the only option for making significant progress," noted SimCenter Principal Investigator and co-Director Sanjay Govindjee. "It is exciting to see civil engineers learning these new technologies and applying them to real-world problems."
Geotechnical Machine Learning
The 2011 Christchurch earthquake in New Zealand caused widespread damage, much of which resulted from liquefaction — a process that occurs when a saturated soil loses stiffness in response to an applied stress, such as during an earthquake.
The quake also generated copious amounts of high-quality geotechnical data. This data enabled Maria Giovanna Durante, a Marie Sklodowska-Curie Fellow at the University of Calabria in Italy and Ellen Rathje, professor of Civil, Architectural, and Environmental Engineering at UT Austin, to use machine learning approaches to predict liquefaction damage.
"It's one of the first machine learning studies in our area of geotechnical engineering," Durante said.
Durante and Rathje trained the model on TACC systems using data that included water-table depth and peak ground shaking, factors that trigger liquefaction. They then applied their model citywide to 2.5 million locations around the epicenter of the earthquake to determine the displacement, and compared the predictions to field measurements. Writing in Earthquake Spectra, they showed their best machine learning models were 70% accurate at determining the amount of displacement caused by the 2011 event.
Access to Frontera provided Durante and Rathje machine learning capabilities on a scale previously unavailable to the field. "It would have taken years to do this research anywhere else," Durante said. "If you want to run a parametric study, or do a comprehensive analysis, you need to have computational power."

Like Wang, she hopes their machine learning liquefaction models will one day direct first-responders in the aftermath of an earthquake. "Emergency crews need guidance on what areas, and what structures, may be most at risk of collapse and focus their attention there," she said.
Physics-Informed AI for Manufacturing
Whereas Wang and Durante’s research uses primarily real-world data to drive their machine learning models, in some other fields, a purely data-driven approach isn’t possible. This is notably true in nanotechnology and nanomanufacturing, where quantum physics controls the behaviors, and imaging at the resolution required is expensive and time-consuming.
An emerging approach combines physics-based simulations with machine learning — essentially training the AI on virtual data derived from computer models.
Ganesh Balasubramanian, an associate professor of Mechanical Engineering and Mechanics at Lehigh University, is applying this approach to make the design and production of solar cells more efficient.
Balasubramanian uses what he calls ‘physics-informed machine learning’. His research combines coarse-grained simulation — using approximate molecular models that represent the organic materials — and machine learning. The combination prevents artificial intelligence from coming up with unrealistic solutions, Balasubramanian believes.
“A lot of research uses machine learning on raw data,” Balasubramanian said. “But more and more there’s an interest in using physics-educated machine learning. That’s where I think the most benefit lies.”
Writing in Computational Materials Science in February 2021, Balasubramanian, graduate student Joydeep Munshi (now a postdoc at Argonne National Laboratory), and collaborators described results from a hybrid simulation/machine learning study on Frontera that identified the materials and production processes for solar cells that would generate the greatest energy conversion efficiency while maintaining structural strength and stability. Doing so reduced the time required to reach an optimal manufacturing process by 40%.
His team also trained a machine learning model to identify potential new molecules with ideal charge transport behaviors for solar cells. “If we discover new materials that perform well, it will reduce the cost of solar power generation devices,” he said.
From the Factory to the Body
AI-engineered real-world systems must be able to survive unexpected conditions and not cause damage if they fail or malfunction. This is particularly the case when it comes to the human body and AI-engineered drugs or treatment methods.
Ying Li is an assistant professor of Mechanical Engineering at the University of Connecticut. He studies and designs nanomedicines 100,000 times smaller than the width of a human hair.
Li is using Frontera to simulate how nanodrugs travel in our blood stream and how to control them in the body. “Because of the size of these particles, this problem is very hard to study using experiments,” Li said.
Writing in Soft Matter in January 2021, Li described the results of a study that looked at how nanoparticles of various sizes and shapes — including nanoworms — move in constricted blood vessels.
“The nanoworm moves like a snake. It can swim between red blood cells, making it easier to escape tight spots,” Li said.
Recently, Li has begun taking advantage of artificial intelligence and machine learning to rapidly generate new nanoparticle designs and methods. Like all AI and machine learning, this approach requires massive quantities of data. And like Balasubramanian, the data comes from simulations on Frontera.
“We ran a lot of simulations with different scenarios to get broad training data,” Li explained. “Then, we pre-train the neural network using the hypothetical data we take from these simulations so they can quickly and efficiently predict the effects.”
With each new generation of supercomputer, computational approaches get more powerful and more predictive, Li believes. “We should take advantage of computational simulations before we run very expensive laboratory experiments to rationalize the problem and provide better guidance.”
Trust, but Quantify
The first explosion of AI-engineered products is probably still a few years from fruition, but a recent paper from Google showed that AI systems can potentially design computer chips that are more efficient than those that any engineer has dreamed up. With these products, however, will come questions regarding trust in their safety, not to mention the scientific reproducibility of the design methods.
For that reason, AI researchers are developing interpretable AI — ways of showing how a model reached a solution — and incorporating uncertainty quantification — a metric of how confident the model is in the solution — into their research.
“These approaches require even more computing, meaning they can only be solved on the largest supercomputers in the world for now,” said Stanzione. “But the effort that goes into developing the models and methods will be available to everyone. That makes HPC the training ground for AI applications across science.”
From trial and error to rational design to AI-enabled manufacturing, engineering is constantly on the move, always looking for better ways to build a better mousetrap (or vaccine). The combination of big data — from observation or simulation — powerful computers, and improved methods are helping drive the next revolution in our built world.